转载备份
影子 DOM(Shadow DOM)
你的 docker stop,它优雅吗? - 无糖拿铁,谢谢
清理Docker的container,image与volume · 零壹軒·笔记
Create a PyPI Mirror Site with devpi-server – SRE
优雅的终止 docker 容器 | iTimothy
Odoo 14 开发者指南第二十一章 性能优化 | Alan Hou 的个人博客
Odoo 14 开发者指南第八章 高级服务端开发技巧 | Alan Hou 的个人博客
kafka 系列:设置日志数据保存过期时间(含某个 topic)、日志策略_NIO4444-CSDN 博客_kafka 配置数据过期时间
Chromium 历史版本离线安装包 - 下载方法
怎样将 props 传递给 {this.props.children} | WebFuse
HappyBaseDoc
用户指南 — HappyBase 1.2.0 文档
安装指南 — HappyBase 1.2.0 文档
API 参考 — HappyBase 1.2.0 文档
PostgreSQL 时间转换
JS 中创建给定长度的数组
GSAP 入门 - 学习中心 - 绿袜
操作系统复习 | Happy Coding
如何理解 ip 路由和操作 linux 的路由表 - CodeAntenna
Elasticsearch 7.11 tokenizer, analyzer and filter 以及 IK 分词配置同义词、远程拓展词库 – Brave new world
podman 容器内访问 host 主机的端口 - 知识库 - BSMI KB 基础标准矿产工业
吐血总结!100 道经典 Python 面试题集锦上(附答案)
中共党史简表(1919 年 - 1949 年)
Dockerfile 详解_万 wu 皆可爱的博客 - CSDN 博客_dockerfile
为你的 Python 应用选择一个最好的 Docker 映像 | 亚马逊 AWS 官方博客
Ubuntu Server 支持中文
docker push | Docker Documentation
docker 创建本地仓库详解 (push/pull)_乱红飞的博客 - CSDN 博客_docker push 本地仓库
基于 Ubuntu 20.04 安装 Kubernetes 1.18
PostgreSQL 集群篇——PostgreSQL 的配置文件解析_51CTO 博客_postGresql
【PostgreSQL】——主从流复制_Teingi 的博客 - CSDN 博客_postgresql 主从复制
PostgreSQL: Documentation: 14: 27.4. Hot Standby
postgresql 主从复制、主从切换_偷懒的小陈的博客 - CSDN 博客_postgresql 主从
Postgres 用户、角色与权限 :: 68hub — 技术博客
中国共产党第二十次全国代表大会在京开幕 一图速览二十大报告
配置 docker 通过代理服务器拉取镜像
IPVS no destination available - Kubernetes 实践指南
Python 风格规范 — Google 开源项目风格指南
互动测试!党的二十大报告 100 题
自定义 ESlint 规则
Java 读取 OpenSSL 生成的秘钥, 进行 RSA 加解密 | 数字魔法
CSS(一)chrome 浏览器表单自动填充默认样式 - autofil_半个 GIS 半个前端的博客 - CSDN 博客
Nginx 多级代理下的真实 IP 透传 - CodeAntenna
Jenkins 环境变量
人民币金额大写规范 - 内蒙古农业大学财务处
[转]nginx 开启 websocket - 浅忆博客
ceph 创建使用 rbd
《三》配置 ceph 存储池 pool - Buxl's blog
基于 K8S 搭建 Ceph 分部署存储 – 唐玥璨 | 博客
序言 · Kubernetes 中文指南——云原生应用架构实战手册
服务器配置 - Redis 安装配置 | 灰帽子 - 任令仓的技术博客
Ubuntu 配置 sudo 命令不需要输入密码_ubuntu sudo 免密_一路向前 - 执着的博客 - CSDN 博客
修改 Docker 数据目录位置,包含镜像位置 - 腾讯云开发者社区 - 腾讯云
微服务架构实践(API Gateway)
微服务网关:从对比到选型,由理论到实践 | Java 程序员进阶之路
聊聊微服务网关
微服务网关:从对比到选型,由理论到实践
odoo 实现表分区 partition
使用 keepalived 搭建高可用服务 - 简书
业务网关的落地实践_文化 & 方法_Qunar 技术沙龙_InfoQ 精选文章
部署 Kubernetes PostgreSQL 实例 | domac 的菜园子
一套包含完整前后端的系统如何在 K8S 中部署?_k8s 前端_木讷大叔爱运维的博客 - CSDN 博客
前端安全系列(二):如何防止 CSRF 攻击? - 美团技术团队
traefik 自定义中间件 | coolcao 的小站
CSRF 原理和实战利用 - FreeBuf 网络安全行业门户
安全运维 - 如何在 Kubernetes 中使用注释对 ingress-nginx 及后端应用进行安全加固配置实践_唯一极客知识分享的技术博客_51CTO 博客
Kubernetes 进阶使用之 Helm,Kustomize
各种加密算法比较
Docker 的三种网络代理配置 · 零壹軒 · 笔记
本文档使用 MrDoc 发布
-
+
首页
【PostgreSQL】——主从流复制_Teingi 的博客 - CSDN 博客_postgresql 主从复制
> 本文由 [简悦 SimpRead](http://ksria.com/simpread/) 转码, 原文地址 [blog.csdn.net](https://blog.csdn.net/weixin_40449300/article/details/110768846) ### 一、前言 [PostgreSQL](https://so.csdn.net/so/search?q=PostgreSQL&spm=1001.2101.3001.7020) 号称是最先进的开源数据库,对标 oracle。不过从使用角度来看,个人认为 pg 过于学院派了,使用上比较不友好。它的设计理念还是很先进的。我今天写本文主要是从主从的角度聊一下 postgreSQL。postgresql 提供了主从复制功能,有基于文件的拷贝和基于 tcp 流的数据传输两种方式。两种方式都是传输 wal 数据,前者是等待生成一个完整的 wal 文件后,才会触发传输,后者是实时传输的。可以看出来基于文件方式的延迟会比较高,而且 wal 文件有可能没来得及传输就被损坏了,造成了这块的数据丢失。基于 tcp 流的方式,延迟非常低,是现在最常见的方式,本篇文章也主要讲述这种方式。不同于基于文件的日志传送,流复制的关键在于 “流”,所谓流,就是没有界限的一串数据,类似于河里的水流,是连成一片的。因此流复制允许一台后备服务器比使用基于文件的日志传送更能保持为最新的状态。比如我们有一个大文件要从本地主机发送到远程主机,如果是按照“流” 接收到的话,我们可以一边接收,一边将文本流存入文件系统。这样,等到 “流” 接收完了,硬盘写入操作也已经完成。 PostgreSQL 物理流复制按照同步方式分为两类: * 异步流复制 * 同步流复制 物理流复制具有以下特点: 1、延迟极低,不怕大事务 2、支持断点续传 3、支持多副本 4、配置简单 5、备库与主库物理完全一致,并支持只读 ### 二、流复制发展历史 pg 在流复制出现之前,使用的就是基于文件的日志传送:对 wal 日志进行拷贝,因此从库始终落后主库一个日志文件,并且使用 rsync 工具同步 data 目录。而流复制出现是从 2010 年推出的 pg9.0 开始的,其历史大致为: 1. 起源:pg9.0 开始支持流式物理复制,用户可以通过流式复制,构建只读备库 (主备物理复制,块级别一致)。流式物理复制可以做到极低的延迟 (通常在 1 毫秒以内)。 2. 同步流复制:pg9.1 开始支持同步复制,但是当时只支持一个同步流复制备节点 (例如配置了 3 个备,只有一个是同步模式的,其他都是异步模式)。同步流复制的出现,保证了数据的 0 丢失。 3. 级联流复制:pg9.2 支持级联流复制。即备库还可以再连备库。 4. 流式虚拟备库:pg9.2 还支持虚拟备库,即就是只有 WAL,没有数据文件的备库。 5. 逻辑复制:pg9.4 开始可以实现逻辑复制,逻辑复制可以做到对主库的部分复制,例如表级复制,而不是整个集群的块级一致复制。 6. 增加多种同步级别:pg9.6 版本开始可以通过 synchronous_commit 参数,来配置事务的同步级别。 ### 三、流复制原理 **3.1 流复制原理图** 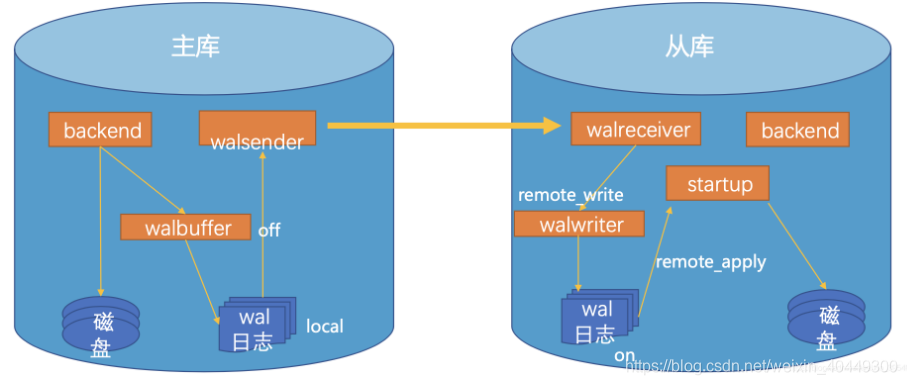 从上图我们可以看到流复制中日志提交的大致流程为: 1、事务 commit 后,日志在主库写入 wal 日志,还需要根据配置的日志同步级别,等待从库反馈的接收结果。 2、主库通过日志传输进程将日志块传给从库,从库接收进程收到日志开始回放,最终保证主从数据一致性。 **3.2、流复制同步级别** PostgreSQL 通过配置 synchronous_commit (enum) 参数来指定事务的同步级别。我们可以根据实际的业务需求,对不同的事务,设置不同的同步级别。 ``` synchronous_commit = off # synchronization level; # off, local, remote_write, or on ``` * remote_apply:事务 commit 或 rollback 时,等待其 redo 在 primary、以及同步 standby(s) 已持久化,并且其 redo 在同步 standby(s) 已 apply。 * on:事务 commit 或 rollback 时,等待其 redo 在 primary、以及同步 standby(s) 已持久化。 * remote_write:事务 commit 或 rollback 时,等待其 redo 在 primary 已持久化; 其 redo 在同步 standby(s) 已调用 write 接口 (写到 OS, 但是还没有调用持久化接口如 fsync)。 * local:事务 commit 或 rollback 时,等待其 redo 在 primary 已持久化; * off:事务 commit 或 rollback 时,等待其 redo 在 primary 已写入 wal buffer,不需要等待其持久化; 不同的事务同步级别对应的数据安全级别越高,对应的对性能影响也就越大。上述从上至下安全级别越来越低。 四、流复制配置过程 --------- PostgreSQL 物理流复制大致过程为: 1、PG 软件安装 2、postgresql.conf 参数配置 3、pg_hba.conf 配置 4、pg_basebackup 方式部署备库 5、配置简单 6、备库与主库物理完全一致,并支持只读 4.1、异步流复制参数配置 postgresql.conf : ``` wal_level = replica # minimal, replica, or logical max_wal_senders = 10 wal_keep_segments = 1024 hot_standby = on ``` pg_hba.conf : ``` host replication postgres # max number of walsender processes # in logfile segments, 16MB each; 0 disables 192.168.7.180/32 md5 ``` standby recovery.conf : ``` recovery_target_timeline = 'latest' standby_mode = on primary_conninfo = 'host=192.168.7.180 port=1921 user=bill password=xxx ``` 4.2、同步流复制参数配置 postgresql.conf : ``` wal_level = replica # minimal, replica, or logical max_wal_senders = 10 # max number of walsender processes wal_keep_segments = 1024 # in logfile segments, 16MB each; 0 disables hot_standby = on synchronous_commit = remote_write、on、remote_apply synchronous_standby_names = 'standby2' ``` pg_hba.conf : ``` recovery_target_timeline = 'latest' standby_mode = on primary_conninfo = 'host=192.168.7.180 port=1921 user=bill password=xxx application_name=standby2' ``` standby recovery.conf : ``` recovery_target_timeline = 'latest' standby_mode = on primary_conninfo = 'host=192.168.7.180 port=1921 user=bill password=xxx application_name=standby2' ``` 另外我们可以通过设置 synchronous_standby_names 参数来指定一个支持同步复制的后备服务器的列表,其支持格式大致为: ``` 1、synchronous_standby_names =standby_name [, ...] 2、synchronous_standby_names =[FIRST] num_sync ( standby_name [, ...]) 3、synchronous_standby_names =ANY num_sync ( standby_name [, ...] ) ``` ### **五、****PostgreSQL** **主备数据库切换** **1****、识别当前库主、备角色:** `方式一:` postgres=# select pg_is_in_recovery(); `结果是f则为主库,t为备库``。` `方式二:` pg_controldata `结果为``cluster state``是in production则为主库;结果为cluster state是in archive recovery则为备库``。` `方式三:` Select pid, application_name, client_addr, client_port, state, sync_state from pg_stat_replication `查询到结果为主库,查询不到结果为备库。` **2****、主备倒换** 在 PostgreSQL 如主库出现异常时,备库如何激活。有 2 种方式: **方式一:**使用 pg_ctl promote 来激活(PostgreSQL9.1 后支持) (1)关闭主库(模拟主库故障): $ pg_ctl stop -m fast (2)在备库上执行 pg_ctl promote 命令激活备库 如果 recovery.conf 变成 recovery.done 表示备库已切换成主库 (3)原主库变备库 在新备库上创建 recovery.conf、.pgpass 文件,内容参考前文章节。启动新备库: $ pg_ctl start **方式二:**备库在 recovery.conf 文件中有个配置项 trigger_file,是激活 standby 的触发文件,通过检测这个文件是否存在,存在则激活 standby 为 master。 (1)在 recovery.conf 中配置触发器文件地址,修改本参数后需要重启备库: recovery_target_timeline = 'latest' standby_mode = on primary_conninfo = 'host=10.10.10.1 port=5432 user= u_standby password=standby123' **_trigger_file = '/home/postgres/pg11/trigger'_** (2)停掉原主库,会发现原备库变为可读写。 $ pg_ctl stop -m fast (3)在备库创建 trigger_file $ touch /home/postgres/pg11/trigger (4)发现原备库变为主库,方法参考 “识别当前库主、备角色”。 **3****、故障的原主库,重新作为备库使用** 在异步流复制(async)模式下,主库故障切换后,可能存在原主库故障时还有数据没来及的复制到备库,这些数据将丢失。(注:PostgreSQL 的 Streaming Replication 是以事务为单位,即使数据未同步完毕,也不会出现备库某个事务只恢复一半的情况,因此事务一致性还是可以保证的。) 此种情况下,原主库的最后一个事务时间戳比复制到原备库(新主库)的事务时间戳更新。比如:倒换前最后几个事务是 100/101/102,故障前流复制到 100 事务,则故障切换后,原主库中最新一个事务是 102,原备库(新主库)中复制的最后一个事务是 100,后续新主库(原备库)将在 100 的基础上,进行新的事务操作。原主库数据、新主库数据出现分叉点。因此,如果希望原主库恢复服务后作为新备库运行,则需要: **方式一:**删库,重搭新备库(详细参考前文备库配置过程) 1、 关闭库,并清空数据(清楚数据即可,不需要重装数据库) pg_ctl stop -m fast rm -rf /var/lib/pgsql/data/* 2、 新备库进行数据基本备份 pg_basebackup …. 3、 启动新备库 pg_ctl start **方式二:**采用 pg_rewind 降级为备库,继续服务 如果你的数据库到达 TB 级别,采用方式一的全量数据基础备份将花费数个小时。为了解决此问题,PostgreSQL9.5 引入了 pg_rewind 功能。原主库(新备库)可以通过 pg_rewind 操作实现故障时间线的回退。回退后再从新主库中获取最新的后续数据。此时,原主库的数据无须进行重新全量初始化就可以继续进行 Streaming Replication,并作为新的 Slave 使用。 ### 六、监控指标 **1. 主库监控** 在主库执行下列 sql,可以获得从库的相关信息。不过有些信息都是由从库汇报上来的,比如 flush_lsn,replay_lsn,会有一些延迟。 ``` postgres=# select * from pg_stat_replication; -[ RECORD 1 ]----+------------------------------ pid | 22219 usesysid | 25411 usename | repl application_name | walreceiver client_addr | 192.168.1.2 client_hostname | client_port | 35442 backend_start | 2020-05-06 14:40:58.271771+08 backend_xmin | state | streaming sent_lsn | 0/70209B0 write_lsn | 0/70209B0 flush_lsn | 0/70209B0 replay_lsn | 0/70209B0 write_lag | flush_lag | replay_lag | sync_priority | 0 sync_state | async reply_time | 2020-05-06 14:41:08.308271+08 ``` **2. 从库监控** ``` postgres=# select * from pg_stat_wal_receiver; -[ RECORD 1 ]---------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- pid | 852 status | streaming receive_start_lsn | 0/7000000 receive_start_tli | 1 received_lsn | 0/7000000 received_tli | 1 last_msg_send_time | 2020-05-06 14:53:59.640178+08 last_msg_receipt_time | 2020-05-06 14:53:59.640012+08 latest_end_lsn | 0/70209B0 latest_end_time | 2020-05-06 14:40:58.293124+08 slot_name | sender_host | 192.168.1.1 sender_port | 15432 conninfo | ... ``` 关于上面主控监控中,从库的关于 wal 的恢复信息获取会存在延迟。不过我们可以直接在从库上实时获取, ``` postgres=# select pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp(); pg_last_wal_receive_lsn | pg_last_wal_replay_lsn | pg_last_xact_replay_timestamp -------------------------+------------------------+------------------------------- 0/70209B0 | 0/70209B0 | 2020-04-30 17:15:24.425998+08 (1 row) ``` ### 七、参考资料 1. [postgreSQL 流复制部署](https://www.niuxiazai.com/article/1736.html) 2. [https://www.cnblogs.com/wy20201111/p/14002403.html](https://www.cnblogs.com/wy20201111/p/14002403.html)
幻翼
2022年10月10日 15:49
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档(打印)
分享
链接
类型
密码
更新密码