转载备份
影子 DOM(Shadow DOM)
你的 docker stop,它优雅吗? - 无糖拿铁,谢谢
清理Docker的container,image与volume · 零壹軒·笔记
Create a PyPI Mirror Site with devpi-server – SRE
优雅的终止 docker 容器 | iTimothy
Odoo 14 开发者指南第二十一章 性能优化 | Alan Hou 的个人博客
Odoo 14 开发者指南第八章 高级服务端开发技巧 | Alan Hou 的个人博客
kafka 系列:设置日志数据保存过期时间(含某个 topic)、日志策略_NIO4444-CSDN 博客_kafka 配置数据过期时间
Chromium 历史版本离线安装包 - 下载方法
怎样将 props 传递给 {this.props.children} | WebFuse
HappyBaseDoc
用户指南 — HappyBase 1.2.0 文档
安装指南 — HappyBase 1.2.0 文档
API 参考 — HappyBase 1.2.0 文档
PostgreSQL 时间转换
JS 中创建给定长度的数组
GSAP 入门 - 学习中心 - 绿袜
操作系统复习 | Happy Coding
如何理解 ip 路由和操作 linux 的路由表 - CodeAntenna
Elasticsearch 7.11 tokenizer, analyzer and filter 以及 IK 分词配置同义词、远程拓展词库 – Brave new world
podman 容器内访问 host 主机的端口 - 知识库 - BSMI KB 基础标准矿产工业
吐血总结!100 道经典 Python 面试题集锦上(附答案)
中共党史简表(1919 年 - 1949 年)
Dockerfile 详解_万 wu 皆可爱的博客 - CSDN 博客_dockerfile
为你的 Python 应用选择一个最好的 Docker 映像 | 亚马逊 AWS 官方博客
Ubuntu Server 支持中文
docker push | Docker Documentation
docker 创建本地仓库详解 (push/pull)_乱红飞的博客 - CSDN 博客_docker push 本地仓库
基于 Ubuntu 20.04 安装 Kubernetes 1.18
PostgreSQL 集群篇——PostgreSQL 的配置文件解析_51CTO 博客_postGresql
【PostgreSQL】——主从流复制_Teingi 的博客 - CSDN 博客_postgresql 主从复制
PostgreSQL: Documentation: 14: 27.4. Hot Standby
postgresql 主从复制、主从切换_偷懒的小陈的博客 - CSDN 博客_postgresql 主从
Postgres 用户、角色与权限 :: 68hub — 技术博客
中国共产党第二十次全国代表大会在京开幕 一图速览二十大报告
配置 docker 通过代理服务器拉取镜像
IPVS no destination available - Kubernetes 实践指南
Python 风格规范 — Google 开源项目风格指南
互动测试!党的二十大报告 100 题
自定义 ESlint 规则
Java 读取 OpenSSL 生成的秘钥, 进行 RSA 加解密 | 数字魔法
CSS(一)chrome 浏览器表单自动填充默认样式 - autofil_半个 GIS 半个前端的博客 - CSDN 博客
Nginx 多级代理下的真实 IP 透传 - CodeAntenna
Jenkins 环境变量
人民币金额大写规范 - 内蒙古农业大学财务处
[转]nginx 开启 websocket - 浅忆博客
ceph 创建使用 rbd
《三》配置 ceph 存储池 pool - Buxl's blog
基于 K8S 搭建 Ceph 分部署存储 – 唐玥璨 | 博客
序言 · Kubernetes 中文指南——云原生应用架构实战手册
服务器配置 - Redis 安装配置 | 灰帽子 - 任令仓的技术博客
Ubuntu 配置 sudo 命令不需要输入密码_ubuntu sudo 免密_一路向前 - 执着的博客 - CSDN 博客
修改 Docker 数据目录位置,包含镜像位置 - 腾讯云开发者社区 - 腾讯云
微服务架构实践(API Gateway)
微服务网关:从对比到选型,由理论到实践 | Java 程序员进阶之路
聊聊微服务网关
微服务网关:从对比到选型,由理论到实践
odoo 实现表分区 partition
使用 keepalived 搭建高可用服务 - 简书
业务网关的落地实践_文化 & 方法_Qunar 技术沙龙_InfoQ 精选文章
部署 Kubernetes PostgreSQL 实例 | domac 的菜园子
一套包含完整前后端的系统如何在 K8S 中部署?_k8s 前端_木讷大叔爱运维的博客 - CSDN 博客
前端安全系列(二):如何防止 CSRF 攻击? - 美团技术团队
traefik 自定义中间件 | coolcao 的小站
CSRF 原理和实战利用 - FreeBuf 网络安全行业门户
安全运维 - 如何在 Kubernetes 中使用注释对 ingress-nginx 及后端应用进行安全加固配置实践_唯一极客知识分享的技术博客_51CTO 博客
Kubernetes 进阶使用之 Helm,Kustomize
各种加密算法比较
Docker 的三种网络代理配置 · 零壹軒 · 笔记
本文档使用 MrDoc 发布
-
+
首页
基于 K8S 搭建 Ceph 分部署存储 – 唐玥璨 | 博客
> 本文由 [简悦 SimpRead](http://ksria.com/simpread/) 转码, 原文地址 [www.tangyuecan.com](https://www.tangyuecan.com/2020/02/17/%E5%9F%BA%E4%BA%8Ek8s%E6%90%AD%E5%BB%BAceph%E5%88%86%E9%83%A8%E7%BD%B2%E5%AD%98%E5%82%A8/) ### 版本依赖      搭建思路 ---- 很多高级运维人员都 2020 年了对于 K8S 的存储大部分都是采用主机路径大法这样的系统搭建简单但是极其不科学,运维者自己也清楚但是为什么不直接搭一套 Ceph 呢,那就是在系统上搭建 Ceph 太 TM 复杂了,我看了整个文档之后也是头皮发麻的。 首先我们不是直接在虚拟机或者物理上直接搭建 Ceph,那样的话……,而且当前各路大神的集群思路都是容器化,所以在已有的 K8S 集群上再搭建 Ceph 就非常合理,重要的是我们最终只需要通过 K8S 就可以维护整个集群状态不需要再 shell 到服务器上各种操作,不光是开发而且就连运维都是一个 _Serverless_ 状态,多么的帅气是吧,所以我们的思路就是一个:全面容器化。 为何搭建 ---- 首先 K8S 必须要有分部署存储,如果没有的话根本算不上集群,如果不理解这一步那需要去回炉学习一下 K8S 才行。 其次是我其实已经搭建了一套基于 _GlusterFS_ 署存储系统,但是这套方案不是容器运行的维护的时候需要我 shell 到服务器上这就已经很蛋疼了,同时有一个致命的缺陷那就是 _GlusterFS_ 会建立一大堆 TCP 链接几乎上万级别在长时间运行之后(大概一个多月左右)存储说挂就挂了而且没法自动恢复,稳定性有点捉急。 但是 Ceph 不一样,假设 K8S 是油条那么 Ceph 就是豆浆,基本上都是一个通识了,核心原因是它能够提供非常稳定的块存储系统,并且 K8S 对 Ceph 放出了完整的生态,几乎可以说是全面兼容。 搭建前提 ---- 前提比较清楚首先需要如下东西: * 正常运行的多节点 K8S 集群,可以是两个节点也可以是更多。 * 每一个节点需要一个没有被分区的硬盘,最好大小一致不然会浪费。 没错其实就是一个要求,必须有集群才能进行容器管理,必须有硬盘才能做存储这些都是基础。 搭建流程 ---- #### 什么是 rook 终于到流程了,这里我还是需要先说一下我们搭建 Ceph 为了最简单的实现也不是手动拉取各种镜像然后配置这样的话和在物理机上搭建没有什么区别,既然已经在 K8S 上运行了那么我们其实可以通过 ROOK 自动帮我们进行分部署存储的创建,那么问题来了什么 ROOK?  Ceph Rook 如何与 Kubernetes 集成 * Rook 是一个开源的 cloud-native storage 编排, 提供平台和框架;为各种存储解决方案提供平台、框架和支持,以便与云原生环境本地集成。 * Rook 将存储软件转变为自我管理、自我扩展和自我修复的存储服务,它通过自动化部署、引导、配置、置备、扩展、升级、迁移、灾难恢复、监控和资源管理来实现此目的。 * Rook 使用底层云本机容器管理、调度和编排平台提供的工具来实现它自身的功能。 * Rook 目前支持 Ceph、NFS、Minio Object Store 和 CockroachDB。 * Rook 使用 Kubernetes 原语使 Ceph 存储系统能够在 Kubernetes 上运行。 所以在 ROOK 的帮助之下我们甚至可以做到一键编排部署 Ceph,同时部署结束之后的运维工作 ROOK 也会介入自动进行实现对存储拓展,即便是集群出现了问题 ROOK 也能在一定程度上保证存储的高可用性,绝大多数情况之下甚至不需要 Ceph 的运维知识都可以正常使用。  ROOK 运行机制 既然已经引入了 ROOK 那么后面的部署步骤就简单了很多可以参考:[ROOK 官方文档](https://rook.github.io/docs/rook/v1.2/ceph-quickstart.html)。 首先便是获取 rook 仓库:[https://github.com/rook/rook.git](https://github.com/rook/rook.git) #### 安装常规资源 首先在 rook 仓库之中的 [cluster/examples/kubernetes/ceph/common.yaml](https://github.com/rook/rook/blob/master/cluster/examples/kubernetes/ceph/common.yaml) 文件,这个文件是 K8S 的编排文件直接便可以使用 K8S 命令将文件之中编排的资源全部安装到集群之中,需要注意的只有一点,如果你想讲 rook 和对应的 ceph 容器全部安装到一个特定的项目之中去,那么建议优先创建项目和命名空间,common 文件资源会自动创建一个叫做 rook-ceph 的命名空间,后续所以的资源与容器都会安装到这里面去。运行 yaml 文件部署常规资源: kubectl create -f common.yaml #运行 common.yaml 文件 kubectl create -f common.yaml ``` #运行common.yaml文件 kubectl create -f common.yaml ``` #### 安装操作器 操作器是整个 ROOK 的核心,后续的集群创建、自动编排、拓展等等功能全部是在操作器的基础之上实现的,操作器具备主机权限能够监控服务所依赖的容器运行情况和主机的硬盘变更情况,相当于大脑,编排文件为 [/cluster/examples/kubernetes/ceph/operator.yaml](https://github.com/rook/rook/blob/master/cluster/examples/kubernetes/ceph/operator.yaml) 这里没有什么需要注意的直接运行安装即可: kubectl create -f operator.yaml #运行 operator.yaml 文件 kubectl create -f operator.yaml ``` #运行operator.yaml文件 kubectl create -f operator.yaml ``` 安装完成之后需要等待所有的操作器正常运行之后才能继续还是 ceph 分部署集群的安装: #获取命名空间下运行的 pod,等待所以的 pod 都是 running 状态之后继续下一步 kubectl -n rook-ceph get pod #获取命名空间下运行的 pod,等待所以的 pod 都是 running 状态之后继续下一步 kubectl -n rook-ceph get pod ``` #获取命名空间下运行的pod,等待所以的pod都是running状态之后继续下一步 kubectl -n rook-ceph get pod ``` #### 创建 Ceph 集群 这里就厉害了,直接通过一个 yaml 编排文件能够对整个 Ceph 组件部署、硬盘配置、集群配置等一系列操作,仅仅这一步便完成了集群的搭建。编排文件为 [/cluster/examples/kubernetes/ceph/cluster.yaml](https://github.com/rook/rook/blob/master/cluster/examples/kubernetes/ceph/cluster.yaml) 但是这里也需要进行一定的基础配置与修改才能继续,cluster.yaml 文件内容如下: apiVersion: ceph.rook.io/v1 dataDirHostPath: /var/lib/rook continueUpgradeAfterChecksEvenIfNotHealthy: false #这里是最重要的,mon 是存储集群的监控器,我们 K8S 里面有多少主机这里的就必须使用多少个 mon allowMultiplePerNode: false #监控面板是否使用 SSL,如果是使用 8443 端口,不是则使用 7000 端口,由于这是运维人员使用建议不启用 rulesNamespace: rook-ceph removeOSDsIfOutAndSafeToRemove: false osdMaintenanceTimeout: 30 manageMachineDisruptionBudgets: false machineDisruptionBudgetNamespace: openshift-machine-api apiVersion: ceph.rook.io/v1 kind: CephCluster metadata: name: rook-ceph namespace: rook-ceph spec: cephVersion: image: ceph/ceph:v14.2.6 allowUnsupported: false dataDirHostPath: /var/lib/rook skipUpgradeChecks: false continueUpgradeAfterChecksEvenIfNotHealthy: false mon: #这里是最重要的,mon 是存储集群的监控器,我们 K8S 里面有多少主机这里的就必须使用多少个 mon count: 3 allowMultiplePerNode: false dashboard: #这里是是否启用监控面板,基本上都会使用 enabled: true #监控面板是否使用 SSL,如果是使用 8443 端口,不是则使用 7000 端口,由于这是运维人员使用建议不启用 ssl: true monitoring: enabled: false rulesNamespace: rook-ceph network: hostNetwork: false rbdMirroring: workers: 0 crashCollector: disable: false annotations: resources: removeOSDsIfOutAndSafeToRemove: false storage: useAllNodes: true useAllDevices: true config: disruptionManagement: managePodBudgets: false osdMaintenanceTimeout: 30 manageMachineDisruptionBudgets: false machineDisruptionBudgetNamespace: openshift-machine-api ``` apiVersion: ceph.rook.io/v1 kind: CephCluster metadata: name: rook-ceph namespace: rook-ceph spec: cephVersion: image: ceph/ceph:v14.2.6 allowUnsupported: false dataDirHostPath: /var/lib/rook skipUpgradeChecks: false continueUpgradeAfterChecksEvenIfNotHealthy: false mon: #这里是最重要的,mon是存储集群的监控器,我们K8S里面有多少主机这里的就必须使用多少个mon count: 3 allowMultiplePerNode: false dashboard: #这里是是否启用监控面板,基本上都会使用 enabled: true #监控面板是否使用SSL,如果是使用8443端口,不是则使用7000端口,由于这是运维人员使用建议不启用 ssl: true monitoring: enabled: false rulesNamespace: rook-ceph network: hostNetwork: false rbdMirroring: workers: 0 crashCollector: disable: false annotations: resources: removeOSDsIfOutAndSafeToRemove: false storage: useAllNodes: true useAllDevices: true config: disruptionManagement: managePodBudgets: false osdMaintenanceTimeout: 30 manageMachineDisruptionBudgets: false machineDisruptionBudgetNamespace: openshift-machine-api ``` 相同的直接通过编排指令部署集群: kubectl create -f cluster.yaml #运行 cluster.yaml 文件 kubectl create -f cluster.yaml ``` #运行cluster.yaml文件 kubectl create -f cluster.yaml ``` #### 创建监控面板 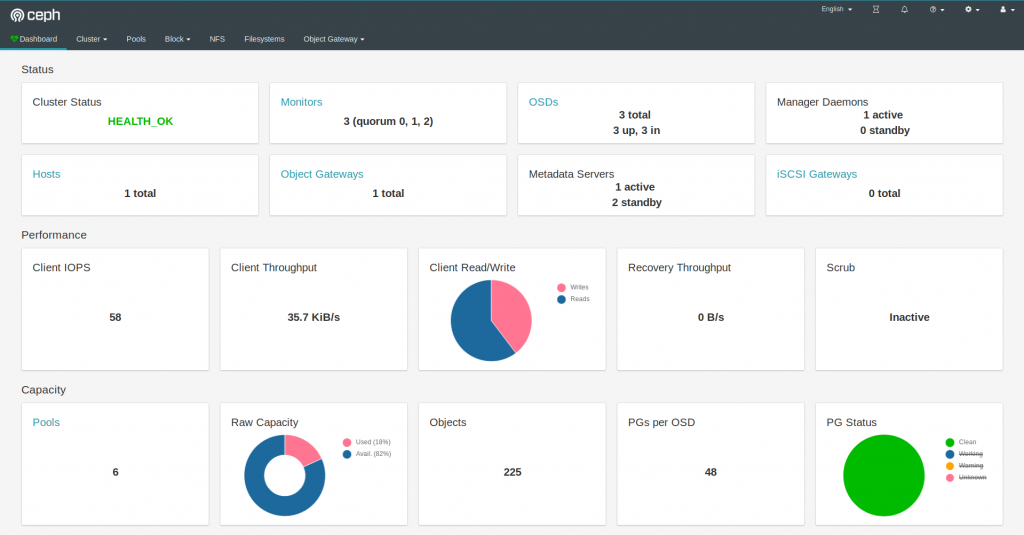 Ceph 控制面板 也是一个 yaml 编排文件能够通过集群将 dashboard 端口给服务出来,也是一句编排指令,如果上面启用了 SSL 则需要使用 [/cluster/examples/kubernetes/ceph/dashboard-external-https.yaml](https://github.com/rook/rook/blob/master/cluster/examples/kubernetes/ceph/dashboard-external-https.yaml) 否则使用同目录下的 [dashboard-external-http.yaml](https://github.com/rook/rook/blob/master/cluster/examples/kubernetes/ceph/dashboard-external-http.yaml) 文件: kubectl create -f dashboard-external-http.yaml kubectl create -f dashboard-external-https.yaml #dashboard 没有启用 SSL kubectl create -f dashboard-external-http.yaml #dashboard 启用 SSL kubectl create -f dashboard-external-https.yaml ``` #dashboard没有启用SSL kubectl create -f dashboard-external-http.yaml #dashboard启用SSL kubectl create -f dashboard-external-https.yaml ``` #### 创建 Ceph 工具 正式环境运维绝大部分问题 Rook 都能购自动解决但是一旦出现无法解决的情况便需要手动对 Ceph 进行配置操作了,所以需要 Ceph 工具,他也是一个容器,运维人员可以直接通过对这个容器的 shell 进行 Ceph 集群的控制(后面有实例),编排文件是 [toolbox.yaml](https://github.com/rook/rook/blob/master/cluster/examples/kubernetes/ceph/toolbox.yaml): kubectl create -f toolbox.yaml #安装 Ceph 工具 kubectl create -f toolbox.yaml ``` #安装Ceph工具 kubectl create -f toolbox.yaml ``` #### 创建存储系统与存储类 集群搭建完毕之后便是存储的创建,目前 Ceph 支持块存储、文件系统存储、对象存储三种方案,K8S 官方对接的存储方案是块存储,他也是比较稳定的方案,但是块存储目前不支持多主机读写;文件系统存储是支持多主机存储的性能也不错;对象存储系统 IO 性能太差不考虑,所以可以根据要求自行决定。 存储系统创建完成之后对这个系统添加一个存储类之后整个集群才能通过 K8S 的存储类直接使用 Ceph 存储。 ##### 块存储系统 + 块存储类 yaml 文件: apiVersion: ceph.rook.io/v1 size: 3 #这里的数字分部署数量,一样有几台主机便写入对应的值 apiVersion: storage.k8s.io/v1 provisioner: rook-ceph.rbd.csi.ceph.com csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph csi.storage.k8s.io/fstype: xfs apiVersion: ceph.rook.io/v1 kind: CephBlockPool metadata: name: replicapool namespace: rook-ceph spec: failureDomain: host replicated: size: 3 #这里的数字分部署数量,一样有几台主机便写入对应的值 --- apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: rook-ceph-block provisioner: rook-ceph.rbd.csi.ceph.com parameters: clusterID: rook-ceph pool: replicapool imageFormat: "2" imageFeatures: layering csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph csi.storage.k8s.io/fstype: xfs reclaimPolicy: Delete ``` apiVersion: ceph.rook.io/v1 kind: CephBlockPool metadata: name: replicapool namespace: rook-ceph spec: failureDomain: host replicated: size: 3 #这里的数字分部署数量,一样有几台主机便写入对应的值 --- apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: rook-ceph-block provisioner: rook-ceph.rbd.csi.ceph.com parameters: clusterID: rook-ceph pool: replicapool imageFormat: "2" imageFeatures: layering csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph csi.storage.k8s.io/fstype: xfs reclaimPolicy: Delete ``` ##### 文件系统存储 yaml 文件: apiVersion: ceph.rook.io/v1 size: 3 #这里的数字分部署数量,一样有几台主机便写入对应的值 size: 3 #这里的数字分部署数量,一样有几台主机便写入对应的值 preservePoolsOnDelete: true apiVersion: ceph.rook.io/v1 kind: CephFilesystem metadata: name: myfs namespace: rook-ceph spec: metadataPool: replicated: size: 3 #这里的数字分部署数量,一样有几台主机便写入对应的值 dataPools: - replicated: size: 3 #这里的数字分部署数量,一样有几台主机便写入对应的值 preservePoolsOnDelete: true metadataServer: activeCount: 1 activeStandby: true ``` apiVersion: ceph.rook.io/v1 kind: CephFilesystem metadata: name: myfs namespace: rook-ceph spec: metadataPool: replicated: size: 3 #这里的数字分部署数量,一样有几台主机便写入对应的值 dataPools: - replicated: size: 3 #这里的数字分部署数量,一样有几台主机便写入对应的值 preservePoolsOnDelete: true metadataServer: activeCount: 1 activeStandby: true ``` ##### 文件系统存储类 yaml 文件: apiVersion: storage.k8s.io/v1 provisioner: rook-ceph.cephfs.csi.ceph.com csi.storage.k8s.io/provisioner-secret-name: rook-csi-cephfs-provisioner csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph csi.storage.k8s.io/node-stage-secret-name: rook-csi-cephfs-node csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: csi-cephfs provisioner: rook-ceph.cephfs.csi.ceph.com parameters: clusterID: rook-ceph fsName: myfs pool: myfs-data0 csi.storage.k8s.io/provisioner-secret-name: rook-csi-cephfs-provisioner csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph csi.storage.k8s.io/node-stage-secret-name: rook-csi-cephfs-node csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph reclaimPolicy: Delete ``` apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: csi-cephfs provisioner: rook-ceph.cephfs.csi.ceph.com parameters: clusterID: rook-ceph fsName: myfs pool: myfs-data0 csi.storage.k8s.io/provisioner-secret-name: rook-csi-cephfs-provisioner csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph csi.storage.k8s.io/node-stage-secret-name: rook-csi-cephfs-node csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph reclaimPolicy: Delete ``` 问题解决 ---- 正常按照上述流程之后或多或少集群状态可能有点问题我这里将我遇到的问题统一说一下并且提供其对应的解决方案: #### PG 数量不足: 这个问题是创建存储系统时的存储池时没有给每一个池足够的 PG 所以导致的存储集群警告修复也比较容易可以通过 Ceph 工具运行 Ceph 命令进行配置: ceph osd pool set 池名称 pg_num 池数量 #获取 Ceph 系统之中池的列表 ceph osd pool ls # 设置一个池的 PG 数量 ceph osd pool set 池名称 pg_num 池数量 ``` #获取Ceph系统之中池的列表 ceph osd pool ls #设置一个池的PG数量 ceph osd pool set 池名称 pg_num 池数量 ``` #### OSDs 数量不足三个 这个问题出现的原因是在创建 Ceph 集群的时候由于只有两台主机所以只是用了两个 MON 导致的,这里也比较容易进行修改,可用通过 rook-config-override 映射重新配置 Ceph 从而解决这个警告: kubectl -n rook-ceph edit configmap rook-config-override -o yaml osd pool default size = 2 #配置 osd 默认数量为 2 creationTimestamp: 2018-12-03T05:34:58Z name: rook-config-override uid: 229e7106-f6bd-11e8-bec3-6c92bf2db856 resourceVersion: "40803738" selfLink: /api/v1/namespaces/rook-ceph/configmaps/rook-config-override uid: 2c489850-f6bd-11e8-bec3-6c92bf2db856 #修改 Ceph 配置 kubectl -n rook-ceph edit configmap rook-config-override -o yaml #自动打开对应的 yaml 文本 apiVersion: v1 data: config: | [global] #添加全局自定义配置 osd pool default size = 2 #配置 osd 默认数量为 2 kind: ConfigMap metadata: creationTimestamp: 2018-12-03T05:34:58Z name: rook-config-override namespace: rook-ceph ownerReferences: - apiVersion: v1beta1 blockOwnerDeletion: true kind: Cluster name: rook-ceph uid: 229e7106-f6bd-11e8-bec3-6c92bf2db856 resourceVersion: "40803738" selfLink: /api/v1/namespaces/rook-ceph/configmaps/rook-config-override uid: 2c489850-f6bd-11e8-bec3-6c92bf2db856 ``` #修改Ceph配置 kubectl -n rook-ceph edit configmap rook-config-override -o yaml #自动打开对应的yaml文本 apiVersion: v1 data: config: | [global] #添加全局自定义配置 osd pool default size = 2 #配置osd默认数量为2 kind: ConfigMap metadata: creationTimestamp: 2018-12-03T05:34:58Z name: rook-config-override namespace: rook-ceph ownerReferences: - apiVersion: v1beta1 blockOwnerDeletion: true kind: Cluster name: rook-ceph uid: 229e7106-f6bd-11e8-bec3-6c92bf2db856 resourceVersion: "40803738" selfLink: /api/v1/namespaces/rook-ceph/configmaps/rook-config-override uid: 2c489850-f6bd-11e8-bec3-6c92bf2db856 ``` #### OSD 无法找到集群控制器导致无法启动服务 OSD 服务本质上就是对一个硬盘的控制服务,每一次对 OSD 重新部署需要兼顾同一个版本,如果出现这个问题说明上层控制版本与 OSD 版本不一致,通过对集群的 operator 操作器进行重启便可以实现对整体版本的更新从而保证硬盘 OSD 能够正常启动。首先重新部署 OSD 使其处于故障状态,其次重启 operator 他会寻找异常 OSD 并且从链路上重新启动。 #### OSD 无法找到逻辑卷导致无法启动服务 OSD 服务需要依靠之前建立的逻辑卷才能启动这一步是在 OSD 核心服务启动之前完成的,出现这个问题是由于宿主机没有安装 LVM2(逻辑卷管理器)导致的,通过对 LVM2 组件的安装之后重启节点服务器便可以使其恢复正常。重启服务器还是有一定的风险确定备份与容错手段全部建立完毕之后再执行。 #### OSD 服务内存泄露问题 一旦发生数据重建或者数据移动的时候各个相关节点的 OSD 服务占用内存会增加,最终导致集群节点失效死锁的情况,目前不知道如何解决这个问题,内存增长的过程比较缓慢,目前只能长期监控,当内存达到一个峰值之后手动重启,有谁知道这个东西怎么解决的话告诉我一声。 #### 硬盘识别不到或者硬盘已经加入 LVM 这个问题足足搞了我一天的时间,一点点式出来的。找不到硬盘的原因是硬盘已经经过分区了,但是如果你将一个硬盘的分区删除之后有会爆出硬盘已经加入 LVM 组的错误,这个问题也是对 Linux 卷系统了解不足导致的,解决方案就是将逻辑卷组删除即可,在硬盘无分区的情况下: #查看逻辑卷情况 lsblk # 删除逻辑卷 / dev/vg0/lv0 lvremove /dev/vg0/lv0 # 查看逻辑卷组 vgs # 删除逻辑卷组 vg0 vgremove vg0 ``` #查看逻辑卷情况 lsblk #删除逻辑卷/dev/vg0/lv0 lvremove /dev/vg0/lv0 #查看逻辑卷组 vgs #删除逻辑卷组vg0 vgremove vg0 ``` 总结 -- 终于摆脱了掉 GlusterFS 存储卷失效的噩梦,晚上可以安心睡觉了。
幻翼
2022年12月14日 18:14
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档(打印)
分享
链接
类型
密码
更新密码